Tools for text normalization and diachronic analysis
Tools for text normalization and diachronic analysis
AMU Faculty of Mathematics and Computer Science
Tools for diachronic text analysis are used to date and normalize texts as well as to search through texts.
Infrastructure components
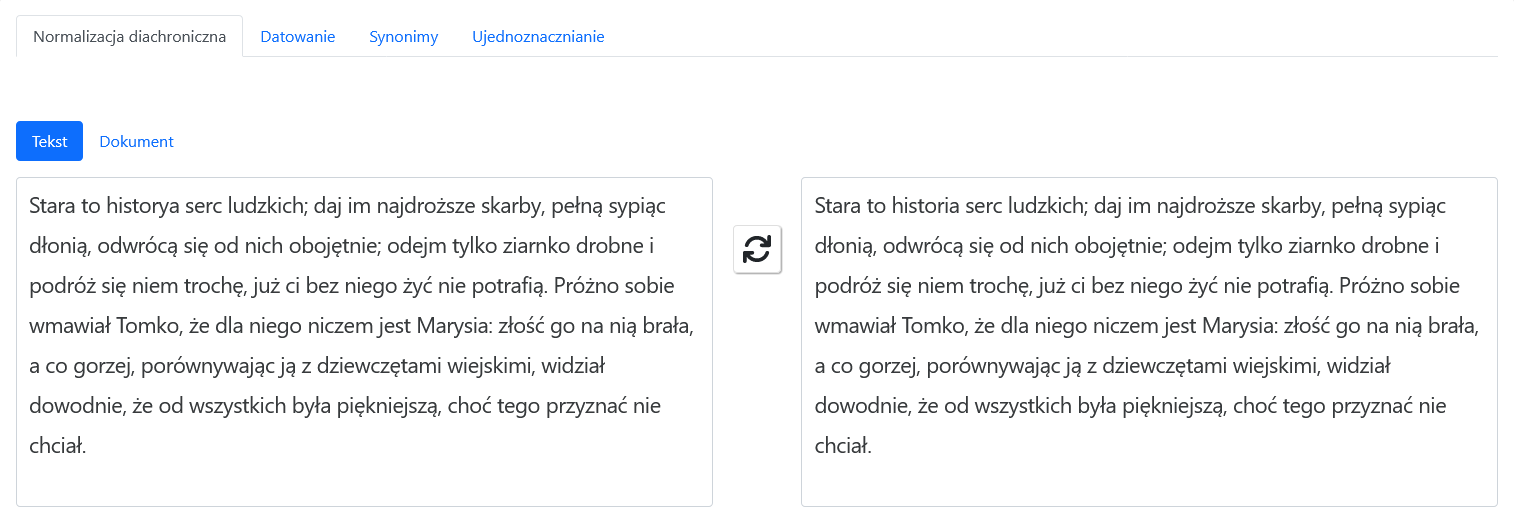
- a diachronic normalizer: software for automatic diachronic normalization of Polish texts, it makes historical texts more “contemporary” by translating them to contemporary language, as a result the archives can be searched using today’s keywords
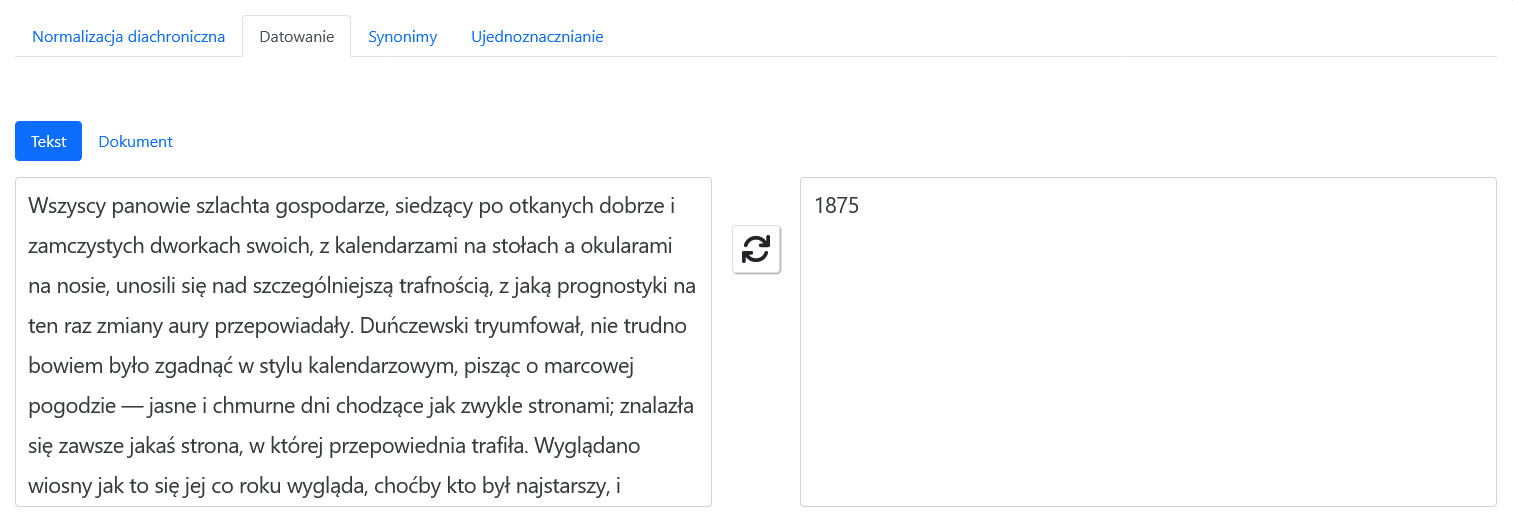
- software for text dating: a date when a text was created can be estimated with an average accuracy of 14 years
- software for replacing words with contemporary synonyms: it searches for historical words and replaces them with their contemporary equivalents with the same or similar meaning
- software for searching texts for the same persons referred to using different names (e.g. characters in literary texts)
About infrastructure
A user inputs a text (from the keyboard or a file). The text is displayed in the editor window. At user request the text can be processed using one of the four functions: diachronic normalization, automatic dating, replacing words with their contemporary equivalents, looking for references to persons. The result of the processing is displayed in a window next to the source text window.
Who is it for?
- Researchers of old literature
- Researchers of diachronic linguistics
- Historians
- Archeologists
Who is it for?
What can the tools be used for?
Thanks to the optimization of scanning algorithms and optical text recognition more and more historical texts are available in digital form. However, most tools for text analysis and processing have been developed for contemporary texts. Our project is one of the first steps to develop tools for effective searching and processing of historical texts.
The methodologies we have been developing can be used to read historical scrolls discovered in Herculaneum, buried under hot mud and ash from the eruption of Mount Vesuvio. The ongoing attempts to read the scrolls rely on AI computer vision algorithms to virtually unroll the scrolls, and language modelling algorithms to provide the missing elements of the language puzzle.
As part of the Dariah-pl project researchers from the AMU Faculty of Mathematics and Computer Science organized an open machine learning competition “Challenging America” (Course (gonito.net)). One of the tasks includes automatic gap filling in a section of text in historical English. Algorithms used for the task may in the future prove useful in reading the old Greek text, which for thousands of years were buried at the foot of Mount Vesuvio.
Infrastructure website
https://diachronia.csi.wmi.amu.edu.pl/
Name and contact details of the module coordinator
Professor Krzysztof Jassem (jassem@amu.edu.pl)