
Automated Enrichment Laboratory
Automated Enrichment Laboratory
The Automated Enrichment Laboratory is one of five laboratories that make up the Dariah.lab infrastructure. It offers services for processing source content in order to acquire a representation suitable for automated analysis, and service for metadata enrichment through annotation, both automated and manual.
Machine Interpretable Content Representation
Digital format of source content is not sufficient for its automated analysis. For example, a scan or digital photo of a document or musical score does not suffice to examine its content. It can be easily read by a human, but for an automated analysis a “machine interpretable” representation needs to be generated with technologies such as OCR/HTR (Optical Character / Handwritten Text Recognition) for text documents, both printed and handwritten, ASR (Automatic Speech Recognition) for sound recordings, or OMR (Optical Music Recognition) for musical notation. What is machine interpretable representation? In short, it is a “text” form of the object’s content, usually in XML format with a specific structure. It makes it possible not only to analyze the content, but also to index and search, which greatly increases the accessibility of the object.
Techniques such as OCR, ASR or OMR are based on artificial intelligence methods, more specifically deep machine learning. Their development has been made possible by the increase in computing power and the growth in the amount of data needed to generate models used in the process of image or sound recognition. Solutions in this field are mostly created using deep neural networks, whose versatility and flexibility have made it possible to adapt them to process different types of data and extract features which can be generalized. By combining information corresponding to different features extracted from different layers of a neural network, solutions to more complex problems can be obtained. OCR, ASR and OMR are widely known and used. HTR on the other hand, is still experimental and is just gaining popularity, despite – still – numerous imperfections.
Automated Enrichment Laboratory will offer tools for processing text documents, music staff, speech and music recordings utilizing the above mentioned techniques.
What does machine interpretable representation contain?
In the case of documents and speech recordings, the machine representation includes the text of the document or the speech recording transcript. The text, extracted using OCR/HTR tools, can be supplemented with additional information specifying, for example its position on the document page, and saved in hOCR, ALTO or PAGE format. It can also be a PDF file with a text layer.
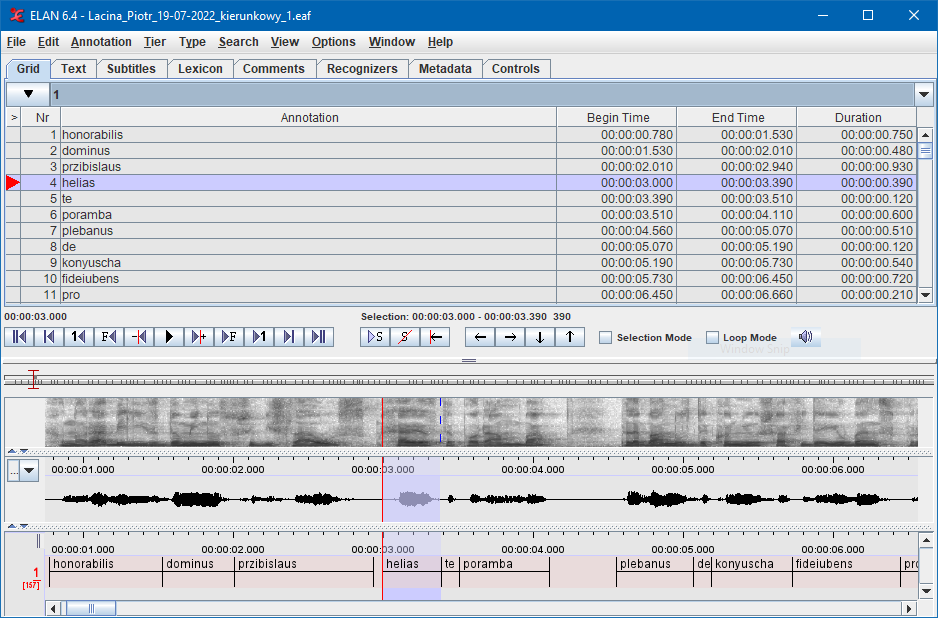
Transcript of an utterance generated by an ASR engine can be annotated with an information about the location of individual words, in this case taking the form of timestamps indicating at what point in time the utterance of the word begins and how long it lasts. One of the formats used for speech transcripts is EAF (ELAN Annotation Format).

In the case of music staff notation, its machine representation includes the textual notation of the piece in one of several formats created for this purpose – MusicXML, MEI, ABC or EsAC. Generating such a format enables further processing and playback of the piece using a number of different music programs. Musical notation has a logical structure far more complex than text and cannot be read sequentially without paying attention to the near and far context. Hence, the task posed to OMR is not easy.
Similarly to speech recordings, music recordings can also be automatically transcribed based on the results of the fundamental frequency extraction, and saved in one of the aforementioned music formats.
Source Content Annotation
Machine representation of content such as documents, literature texts or recordings, enables their analysis with an objective to obtain additional information about the material in question and to enrich knowledge about it. This process is referred to as annotation and involves labeling material elements with labels that categorize them or provide additional information. The Laboratory will offer services for both automated and manual annotation of objects of various types.
What is annotation about?
With regard to text documents or speech transcripts, annotation is about selected linguistic or paralinguistic features of expressions occurring in the text. As a result, each segment (approximately a word or a phrase) is assigned part of speech and grammatical, syntactic or communicative category. Selected segments are also marked as named entities belonging to a certain class (names of people, geographical names, names of organizations, etc.).
Text analysis can also provide information about emotional overtones, structure of the document (division into sections, chapters), subject or the time origin of the document in the case of historical texts. Data resulting from the text analysis constitute various layers of text description. They are usually saved in the form of XML, in particular TEI XML. TEI or Text Encoding Initiative is a format designed to represent texts in digital form.


Automated and manual
Some of the information, such as the above-mentioned linguistic features, can be extracted through automated analysis, while other must be entered manually. In addition, the results of automated analysis (e.g., transcription) may require verification and manual correction. These steps are needed for documents which are characterized by poor legibility due to damage to the source content for example, or the document form (handwriting of different styles), or recordings in which strong background noise makes it difficult to recognize speech correctly.
Manual annotation can be performed with transcription, transliteration, translation and annotation tools developed in the Automated Enrichment Laboratory for text documents and graphics. They are tools for annotation of various aspects of the source content, as well as tools for manual data editing. Manual annotation can be carried out by individual user or by a group of users working together on a given material with a designated person verifying the results and approving them.
Content that can be manually annotated includes textual and graphic data. The Laboratory will provide TEI NPLP tool for creating scholarly digital editions for literary and peri-literary texts. It enables manual annotation of data types: people, places, works, journals, organizations, events. Other functionalities will include comparing versions of scientific digital editions (up to three views simultaneously), tracking chronological changes in the text, linking textual and visual data.
A special case is the annotation of graphic materials which requires maintaining the link between the annotation and the precise location of the image elements to which it refers, ensuring that data can be used for various purposes. Annotation using spatial databases is best suited for indexing, that is, the not full-text annotation of large quantities of both traditional graphic materials such as manuscripts, as well as images or maps. What is important, it does not have to be done with dedicated software, although it is possible with a prototype of such application-service as INDXR. But it can also be done using other widely available applications, components, services and standards related to spatial databases. Thus, the typical and often encountered problem referred to as technological “vendor lock-in” does not occur in this case. As a result, the data produced can be, without transforming it, used in parallel in many different applications.
Music recording annotation
The Laboratory will also offer tools for annotating music recordings. One of the characteristics of sound is its timbre. It is both a subjective characteristic, allowing the listener to distinguish between sounds of the same loudness and pitch from different sources, but it is also an objective, measurable characteristic, which depends on the number and intensity of the elementary components of sound, which are harmonics (aliquots) and noise.
A guitar sounds different than a violin and different than a piano. High tones and low tones have a different timbre. A sound containing few harmonic tones sounds deaf, a higher intensity of lower harmonics gives a timbre described as dark, while higher tones sound bright.
Spectral analysis of sound makes it possible to determine the values of the parameters responsible for the impression of timbre and use this data to recognize musical genre, mood and type of a musical instrument, for example, as well as to recognize the human voice. Tool for analyzing music recordings offered by Automated Enrichment Laboratory will allow for determination of the values of parameters responsible for the impression of timbre and visualization of the similarity of the selected sounds.

What Purpose Can Annotation Serve?
In short, the annotated data enables further more sophisticated analysis and metadata enrichment, but it can also be used in practice. For example, a literary or linguistic researcher can obtain detailed quantitative data on texts in a selected literary genre. Evaluation of the emotional overtones of a press text or a statement in RTV material can be used by media scholars.


