
Laboratorium zautomatyzowanego wzbogacania
Laboratorium zautomatyzowanego wzbogacania
Laboratorium zautomatyzowanego wzbogacania jest jednym z pięciu laboratoriów tworzących infrastrukturę Dariah.lab. Oferuje usługi przetwarzania zgromadzonych materiałów źródłowych w celu pozyskania reprezentacji umożliwiającej automatyczną analizę oraz wzbogacania metadanych poprzez anotację zarówno automatyczną, jak i manualną.
Maszynowo interpretowalna reprezentacja materiałów
Cyfrowy format materiału źródłowego nie gwarantuje jeszcze możliwości jego automatycznej analizy. Przykładowo, skan czy zdjęcie cyfrowe dokumentu lub partytury muzycznej nie wystarcza do zbadania ich zawartości. Jest on łatwy do odczytania przez człowieka, ale dopiero wykorzystanie takich technologii jak OCR/HTR (Optical Character / Handwritten Text Recognition) dla dokumentów tekstowych, zarówno drukowanych, jak i pisanych odręcznie, ASR (Automatic Speech Recognition) dla nagrań dźwiękowych czy OMR (Optical Music Recognition) dla zapisów nutowych, pozwala uzyskać reprezentację „interpretowalną maszynowo”. Czym ona jest? W skrócie zapisem „tekstowym”, zwykle w formacie XML o określonej strukturze, zawartości danego obiektu. Umożliwia ona nie tylko jego analizę, ale również indeksowanie i wyszukiwanie, co znacznie zwiększa dostępność obiektu.
Techniki takie jak OCR, ASR czy OMR bazują na metodach sztucznej inteligencji, a dokładniej głębokiego uczenia maszynowego. Ich rozwój możliwy był dzięki wzrostowi mocy obliczeniowej oraz przyrostowi ilość danych potrzebnych do generowania modeli wykorzystywanych w procesie rozpoznawania obrazów czy dźwięku. Rozwiązania z tej dziedziny tworzone są przeważnie z wykorzystaniem głębokich sieci neuronowych, których uniwersalność i elastyczność umożliwiły ich adaptację do przetwarzania różnego rodzaju danych i wydobywania z nich cech, które następnie są uogólniane. Dzięki połączeniu informacji odpowiadających różnym cechom, pozyskanym z różnych warstw sieci neuronowej, można uzyskać rozwiązanie bardziej złożonych problemów. OCR, ASR i OMR są technologiami powszechnie znanymi i wykorzystywanymi. Technologie HTR mają raczej charakter badawczy i dopiero zyskują popularność, pomimo – ciągle jeszcze – licznych niedoskonałości.
Laboratorium udostępni usługi umożliwiające pozyskanie maszynowo-interpretowalnej reprezentacji dokumentów tekstowych, zapisów nutowych, nagrań mowy oraz nagrań muzycznych.
Co zawiera reprezentacja interpretowalna maszynowo?
W przypadku dokumentów i nagrań wypowiedzi, maszynowa reprezentacja zawiera tekst dokumentu lub tekstowy zapis nagranej wypowiedzi. Tekst, pozyskany z wykorzystaniem narzędzi OCR/HTR może być uzupełniony dodatkowymi informacjami określającymi np. jego położenie na stronie dokumentu i zapisany w formacie hOCR, ALTO czy PAGE. Może to być również plik PDF z warstwą tekstową.
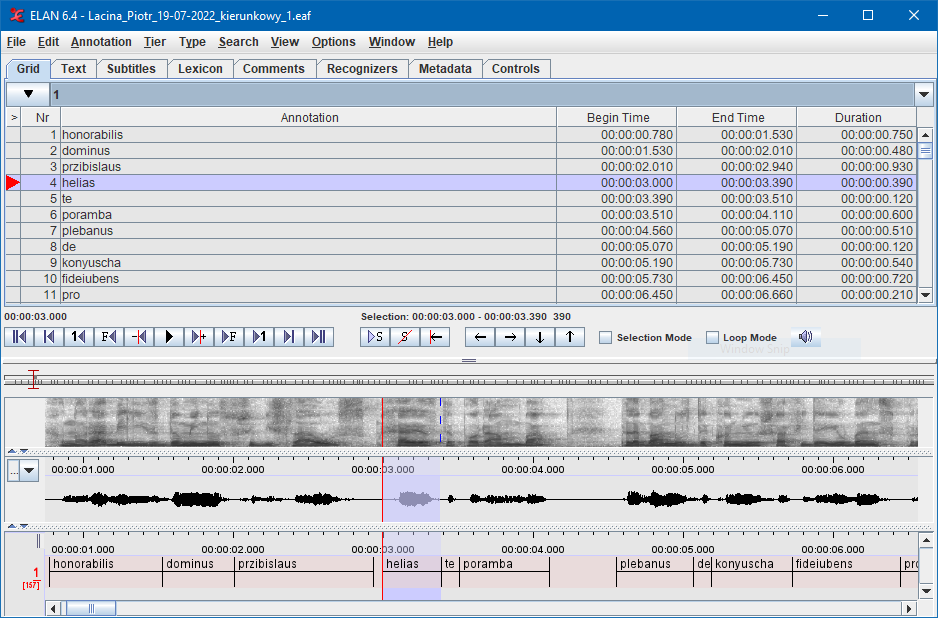
Tekstowy zapis wypowiedzi generowany przez silnik ASR również może być opatrzony informacjami o położeniu poszczególnych wyrazów, w tym przypadku mającymi postać znaczników czasowych określających w którym momencie rozpoczyna się wypowiedź wyrazu i ile trwa. Jednym z formatów wykorzystywanych do zapisu transkrypcji jest EAF (ELAN Annotation Format).

W przypadku dokumentu z zapisem nutowym utworu, maszynowa reprezentacja zawiera zapis tekstowy utworu w jednym z kilku formatów stworzonych do tego celu – MusicXML, MEI, ABC czy EsAC. Wygenerowanie takiego formatu otwiera drogę do dalszego przetwarzania i odtwarzania utworu z wykorzystaniem szeregu programów muzycznych. Notacja muzyczna ma zdecydowanie bardziej złożoną strukturę logiczną niż tekst, nie można jej czytać sekwencyjnie bez zwracania uwagi na bliższy i dalszy kontekst. Stąd też zadanie stawiane przed OMR’em nie należy do najłatwiejszych.
Podobnie jak w przypadku nagrań wypowiedzi, również nagrania muzyczne mogą zostać automatycznie przetranskrybowane na podstawie wyników ekstrakcji częstotliwości podstawowej, a wyniki zapisane w jednym z wyżej wymienionych formatów muzycznych.
Anotacja materiałów źródłowych
Maszynowa reprezentacja zawartości materiałów, takich jak dokumenty, teksty użytkowe i literackie lub nagrania, umożliwia analizę, której celem jest uzyskanie dodatkowych informacji o danym materiale i tym samym wzbogacenie wiedzy na jego temat. Proces ten określany jest mianem anotacji i polega na oznaczeniu elementów materiału etykietami, które je kategoryzują lub wnoszą dodatkowe informacje.
Czego może dotyczyć anotacja?
W odniesieniu do dokumentów tekstowych czy transkrypcji wypowiedzi, anotacja może dotyczyć wybranych cech lingwistycznych lub paralingwistycznych wyrażeń występujących w tekście. W jej wyniku każdemu segmentowi (w przybliżeniu słowu lub frazie) przyporządkowane zostają części mowy i wartości kategorii gramatycznych, składniowych lub komunikacyjnych. Wybrane segmenty zostają też oznaczone jako jednostki nazewnicze wraz z przypisaną im klasą (nazwy osób, nazwy geograficzne, nazwy organizacji itp.).
Analiza tekstu może dostarczyć również informacji o nacechowaniu emocjonalnym, strukturze dokumentu (podziału na sekcje, rozdziały itp.), tematyce czy czasie powstania dokumentu w przypadku tekstów historycznych. Dane pozyskane w wyniku analizy tekstu stanowią warstwy jego opisu. Zapisywane zwykle są w postaci XML, w szczególności TEI XML. TEI czyli Text Encoding Initiative jest formatem przeznaczonym do reprezentacji tekstów w postaci cyfrowej.

Automatycznie i ręcznie
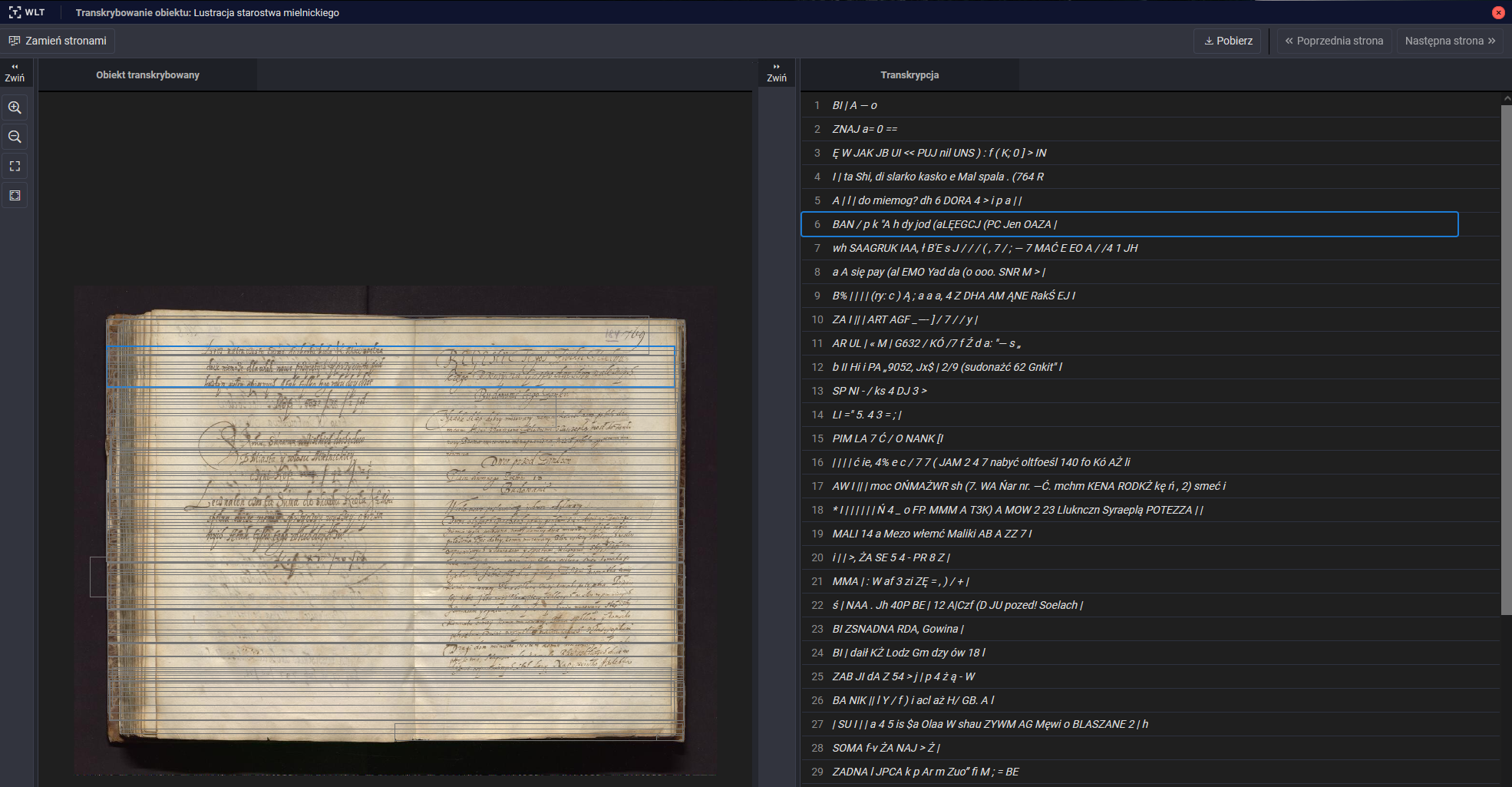
Część informacji wzbogacających, takich jak wymienione powyżej cechy lingwistyczne, można pozyskać w drodze automatycznej analizy, część natomiast musi zostać wprowadzona ręcznie. Ponadto, wyniki automatycznej analizy (np. transkrypcja) mogą wymagać weryfikacji i ręcznej korekty. Dotyczy to materiałów, które charakteryzują się np. słabą czytelnością ze względu na uszkodzenia dokumentów źródłowych czy też formę ich sporządzenia (pismo odręczne o różnym stylu), lub w których silne zakłócenia utrudniają poprawne rozpoznanie mowy.
Takim działaniom służą narzędzia do transkrypcji, transliteracji, tłumaczenia i anotacji dokumentów tekstowych i obiektów graficznych rozwijane w Laboratorium zautomatyzowanego wzbogacania. Są to narzędzia do automatycznej anotacji różnych aspektów zawartości materiałów źródłowych, jak również narzędzia umożliwiające ręczne wprowadzanie i edycję danych materiałów. Ręczna anotacja może być realizowana przez indywidualnych użytkowników lub w trybie pracy grupowej, w ramach której grupa użytkowników wspólnie opracowuje dany materiał, a wyznaczona osoba może weryfikować wyniki i je zatwierdzać.
Materiały podlegające ręcznej anotacji obejmują dane tekstowe i graficzne. W Laboratorium zostanie udostępnione narzędzie TEI NPLP, przeznaczone do tworzenia naukowych edycji cyfrowych dla tekstów literackich i okołoliterackich. Umożliwia ono anotację ręczną typów danych: osoby, miejsca, utwory, czasopisma, organizacje, wydarzenia. Inne funkcjonalności to porównywanie wersji naukowych edycji cyfrowych (jednocześnie do trzech widoków), śledzenie zmian chronologicznych w tekście, powiązanie danych tekstowych i wizualnych.
Szczególny przypadek stanowi anotacja materiałów graficznych z zachowaniem powiązania między anotacją a precyzyjną lokalizacją elementów obrazu, do których się ona odnosi, zapewniając możliwość wykorzystania tych danych do różnych celów. Anotacja z wykorzystaniem baz danych przestrzennych najlepiej sprawdza się w indeksowaniu czyli niepełnotekstowej anotacji dużych ilości zarówno tradycyjnych materiałów graficznych takich jak rękopisy, jak również obrazów czy map. Co istotne nie musi się to odbywać za pomocą dedykowanego oprogramowania, choć jest możliwe za pomocą takiej właśnie prototypowej aplikacji-usługi INDXR. Ale może także być wykonywane z wykorzystaniem innych, standardowych i powszechnie dostępnych aplikacji, komponentów, usług, standardów związanych z obsługą baz danych przestrzennych. Nie występuje więc w tym przypadku typowy i często spotykany problem określany jako technologiczny „vendor lock-in”. Dzięki temu wytwarzane dane mogą być bez ich przekształcania, wykorzystywane równolegle w wielu różnych aplikacjach.
Anotacja nagrań muzycznych
Laboratorium zaoferuje również narzędzia do anotacji nagrań muzycznych. Jedną z cech charakterystycznych dźwięku jest jego barwa. Jest to cecha zarówno subiektywna, pozwalająca słuchaczowi odróżnić od siebie dźwięki o tej samej głośności i wysokości pochodzące z różnych źródeł, ale także jest to cecha obiektywna, mierzalna, zależna od liczby i natężenia elementarnych składowych dźwięku, jakimi są harmoniczne (alikwoty) oraz szumy.
Gitara brzmi inaczej brzmi niż skrzypce i inaczej niż fortepian. Inną barwę mają dźwięki wysokie, a inną niskie. Dźwięk zawierający mało tonów harmonicznych brzmi głucho, większe natężenie niższych harmonicznych daje barwę określaną jako ciemna, zaś wyższych – jako jasna.
Analiza widmowa dźwięku umożliwia wyznaczenie wartości parametrów odpowiedzialnych za wrażenie barwy dźwięku i wykorzystanie tych danych np. do rozpoznawania gatunku muzycznego, nastroju, rodzaju instrumentu muzycznego itp., a także do rozpoznawania głosu ludzkiego. Narzędzie do analizy nagrań muzycznych oferowane w Laboratorium zautomatyzowanego wzbogacania, pozwoli na wyznaczenie wartości parametrów odpowiedzialnych za wrażenie barwy dźwięku oraz wizualizację na ich podstawie podobieństwa wybranych dźwięków.

Czemu może służyć anotacja?
W skrócie, dane zawarte w anotacji umożliwiają dalszą bardziej zaawansowaną analizę i wzbogacanie metadanych, ale mogą też zostać wykorzystane w sposób praktyczny. Przykładowo, badacz literaturoznawca lub językoznawca może uzyskać szczegółowe dane ilościowe na temat tekstów z wybranego gatunku literackiego, a ocena wydźwięku emocjonalnego tekstu prasowego lub wypowiedzi w materiałach RTV może zostać wykorzystana przez medioznawców.


